
カメラと多関節ロボットアームを用い,物体把持を行う,深層学習を利用した制御システムためのRTコンポーネント群を公開しています.
1.概要
![]()
近年,“ロボット×深層学習”が話題となっています.
そこで,これから理解を深めたいと考えている方々向けに,両分野の基礎学習のための教材を開発しました.
深層学習とロボットを組み合わせたシステムを,RTMを用いて実装します.
RTMを用いることによって,ロボットハードウェアやセンサの入れ替え,システムの拡張が簡単にできる構成となっているので,お手持ちの機器で再現が可能です.
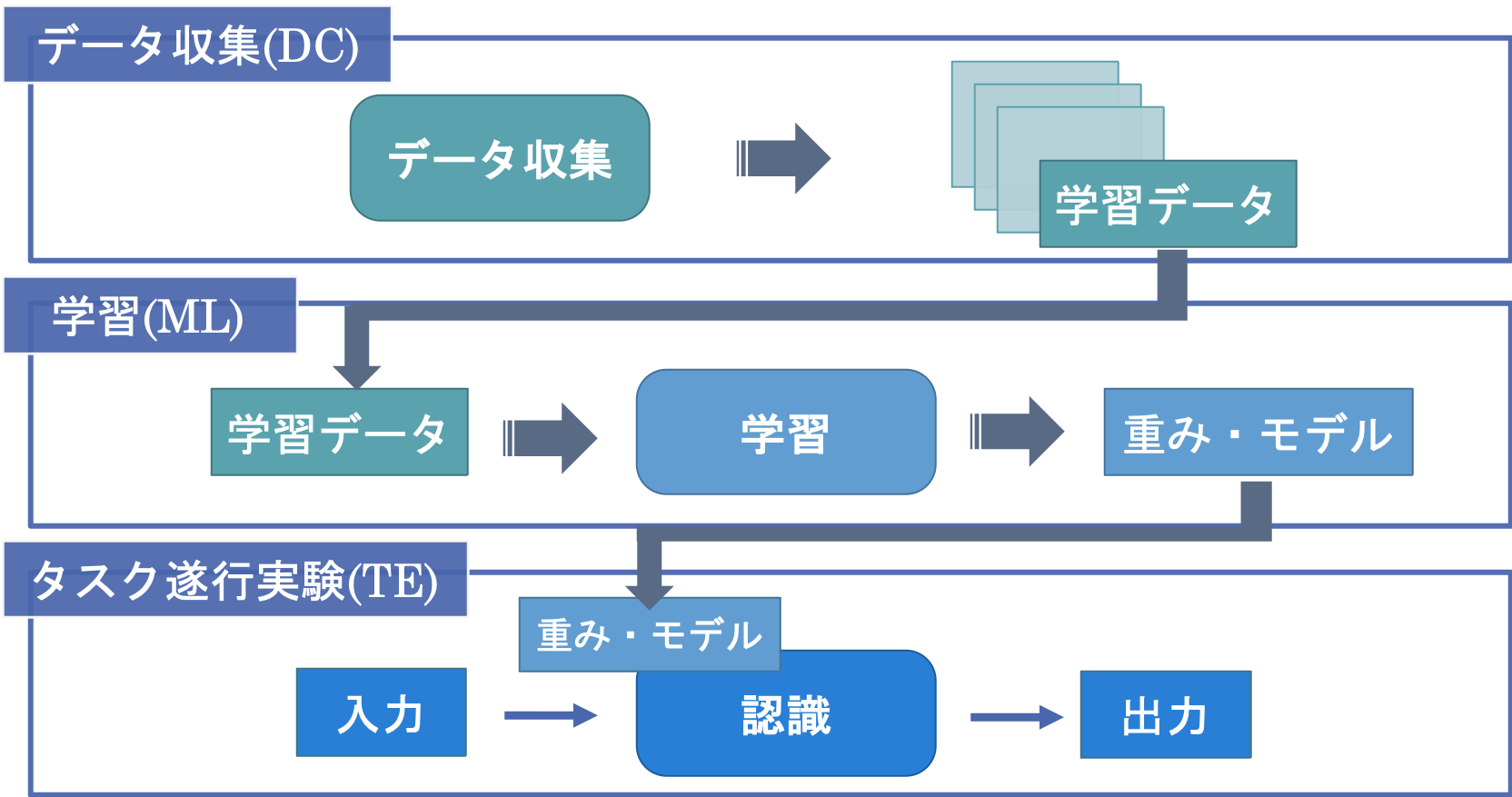
本システムでは,卓上に置いた物体を,カメラに映る位置に関わらずアームで把持することをタスクとし,深層学習器によってカメラ画像から把持位置の予測を行うための,データ収集,学習による結合強度パラメータの推定,および学習後のパラメータを用いたタスクの遂行を行う3つのシステムのセットを開発し,教材としてまとめました.
2.開発環境
- Ubuntu 16.04
- OpenRTM-aist-1.1.2-RELEASE
- CMake3.5.1
- TensorFlow 1.8.0 / TensorFlow-gpu 1.3.0
3.準備
3.1ソフトウェア
RTミドルウェアのインストール
OpenRTM-aistのC++版とJAVA版をインストールしておく必要があります.
公式ウェブサイトからインストーラをダウンロードするか,ソースコードからインストールします.
TensorFlowのインストール
TensorFlowを公式ウェブサイトからインストールします.
Kerasのインストール
Kerasを公式ウェブサイトからインストールします.
RTCs
本システムで利用するRTCは4つです.これらについては4.各機能の概要にてご紹介します.
ArmImageGenerator:https://github.com/ogata-lab/ArmImageGenerator.git
MikataArmRTC:https://github.com/ogata-lab/MikataArmRTC.git
WebCameraRTC:https://github.com/sugarsweetrobotics/WebCamera.git
KerasArmImageMotionGenerator:https://github.com/ogata-lab/KerasArmImageMotionGenerator.git
3.2ハードウェア
実験環境
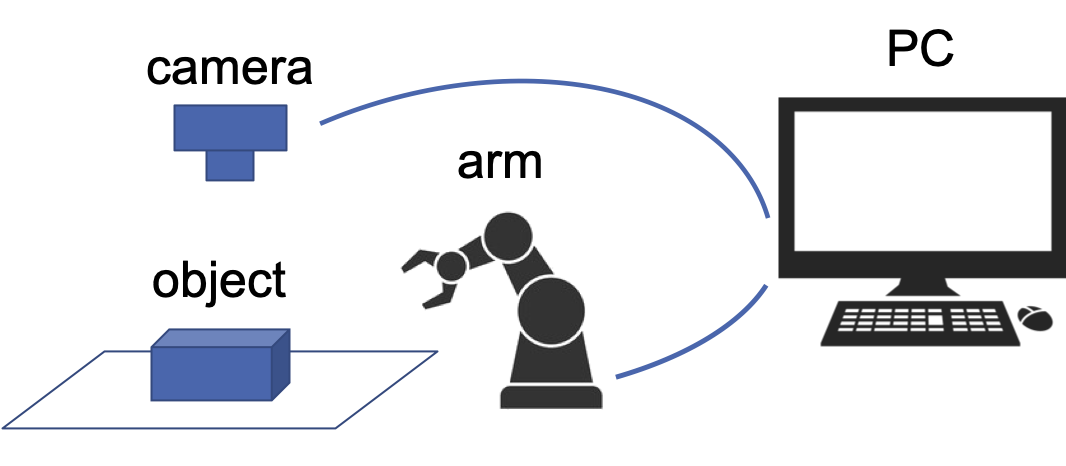
基本的なハードウェアは,ロボットアーム,カメラ及び制御用PCの3点と対象物体で構成されます.
<イメージ図>
ここでは,以下の機器を用いた一例をご紹介します.
・ロボットアーム:ROBOTIS社製,Mikataロボットアーム(卓上で動作する6自由度のロボットアーム)
・カメラ:Logicool社製,C615(USBウェブカメラ)
・三脚:Velbon社製,ELCarmagne538
・対象物体:森永製菓,チョコボールの箱(95mm×45mm×18mm)

<実験環境の参考>
Velbonの三脚に,下向きでカメラを取り付け,Mikataロボットアームの固定台の真上に配置しました.
三脚などを使用する場合,足の位置によってはロボットアームの作業に干渉するので,注意してください.
カメラの画角は,手動で調整しました.カメラの画角が変わると,学習したデータを適用することが難しくなるので,データ収集の姿勢と,把持実験時のカメラ姿勢は,変更しないように注意してください.

<カメラ画像の参考>
また,ロボットアームは長時間の実験を行っても動くことがないように,固定されていると良いでしょう.
4.各機能の概要
本システムのユースケースは,以下の3つの段階に分けることができます.
1) データの収集(Data Collecting, DC)
2) 学習モデルを生成する学習処理(Machine Learning, ML)
3) 学習モデルを用いて行う処理(Task Execution, TE)

4.1データ収集(Data Collecting,DC)
深層学習を行うには,多量のデータが必要となります.そこで,まず第1段階では,自動的にデータ収集を行います.
順番は以下の通りです.
1. 最初にロボットに物体を持たせてから開始
2. 以下,繰り返す
(1) ランダムに生成したテーブル上の位置姿勢(x, y, θ)に対してハンドを移動
(2) 物体を安全に配置
(3) アームが避けてからカメラで撮影
(4) カメラ画像と物体を配置した座標をセットとしてファイルに保存
(5) 同じ座標にある物体をアームで再び把持
以上の動作により,卓上に置かれた物体を対象としたカメラ画像と,物体の位置姿勢のペアを1つのデータとして収集しました。
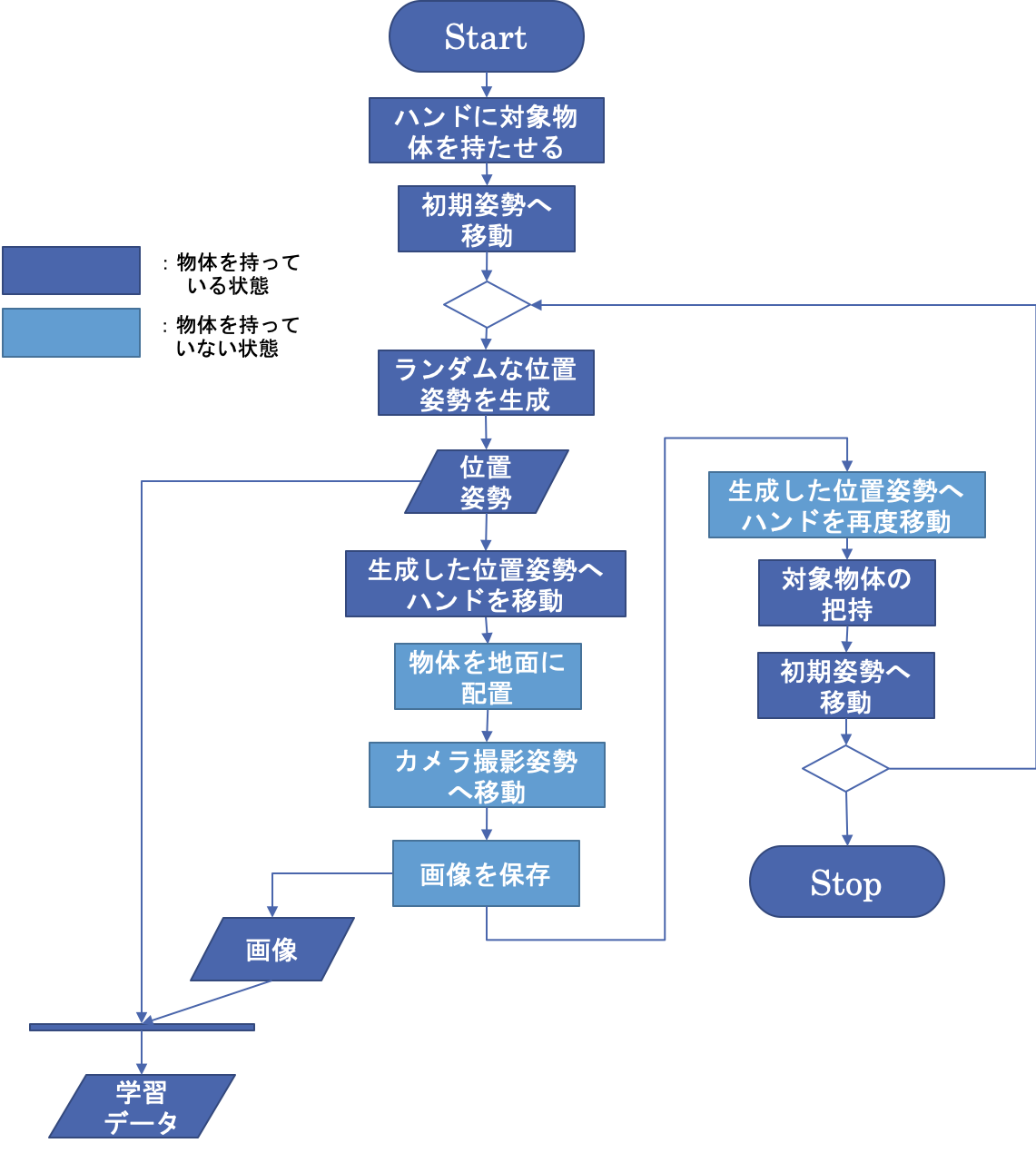
データ収集は,ArmImageGenerator,MikataArmRTC,WebCameraRTCの3つのコンポーネントから構成されます.
ArmImageGenerator
アームによる対象物体の配置・取り出しと,カメラによる撮影データの取得及びそれらの保存を行います.
収集された画像と位置姿勢のデータをまとめたcsvファイルはArmImageGenerator/build/src/(日時)/の中に保存されます.
こちらから取得できます.
ArmImageGenerator:https://github.com/ogata-lab/ArmImageGenerator.git
MikataArmRTC
ROBOTIS社製“Mikataロボットアーム”の制御をします.
こちらから取得できます.
MikataArmRTC:https://github.com/ogata-lab/MikataArmRTC.git
gitでダウンロードする場合には,
$ git submodule update --init --recursive
を使用することをお勧めします.
WebCameraRTC
USBカメラからの画像を取得します.
こちらから取得できます.
WebCameraRTC:https://github.com/sugarsweetrobotics/WebCamera.git
4.2学習(Machine Learning,ML)
第2段階となる学習では,収集した教師データに対して深層学習器を適用し,収集したカメラ画像を入力とし,対象物を把持可能な手先位置姿勢を出力とするような予測器の獲得を目指しました.
本システムでは,収集したデータをそのまま読み込んで実行することで,深層学習を行なった後の認識器のパラメータが獲得できるスクリプトを用意しました.
こちらからソースコードをダウンロードしてください.
学習用サンプルスクリプト:https://github.com/ogata-lab/Basic-Learning-Kit-of-Robot-System-Development-using-DL.git
新しいフォルダを作成し,その中にダウンロードしたファイルを配置する事をお勧めします.
L39の”log_dir = ‘/~/’ “を編集し,DCで収集したデータがあるフォルダを指定してください.
4.3タスク遂行実験(Task Execution,TE)
ここでは,前段階で得られた学習モデルから,画像認識器を構成し,多関節ロボットアームによる把持作業を行います.カメラから得られる 画像情報を入力として,アームの目標手先位置・姿勢を推定し,実際にリーチングを行います.
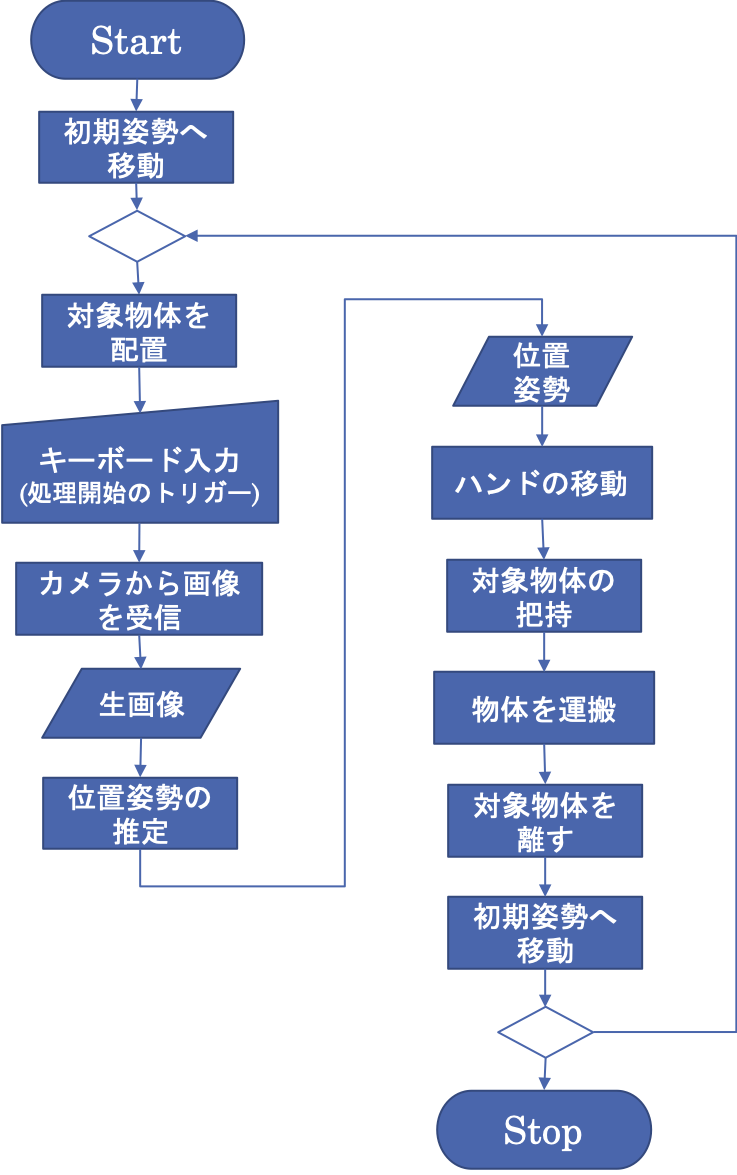
タスク遂行実験は,KerasArmImageMotionGenerator,MikataArmRTC,WebCameraRTCの3つのコンポーネントから構成されます.この内,MikataArmRTCとWebCameraRTCに関しては,4.1のデータ収集で使用したコンポーネントと同一のコンポーネントです.
KerasArmImageMotionGenerator
カメラ画像による対象物体の位置・姿勢推定と,アームへのその位置へのリーチング指令を行います.
最初にIDLファイルをコンパイルするために,Idlcompile.shかIdlcompile.batを実行する必要があります.Idlcompile.shまたはIdlcompile.batのL2「-I”/Users/~/idl/”」を編集した後,利用してください.
こちらから取得できます.
KerasArmImageMotionGenerator:https://github.com/ogata-lab/KerasArmImageMotionGenerator.git
5.実行方法
本システムは,カメラ画像と物体位置の教師データ を自動生成するシステム(DC system),学習をおこなうためのスクリプト(ML system)及び学習後のパラメータを用いてタスクを実行するシステム(TE system)の3つを実装しました.
DCとTEの段階では,RTMを用いて,実機を動かします.
5.1データ収集(Data Collecting,DC)
RTM及び4.1で取得したArmImageGenerator,MikataArmRTC,WebCameraRTCの3つのコンポーネントを起動します.
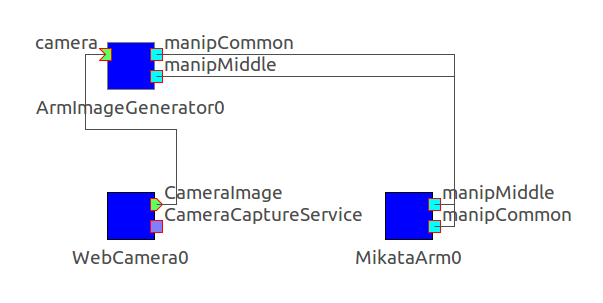
各コンポーネントを上図のように接続します.
コンフィグレーションから,“preview_window”を“true”にすると,Webカメラで取得した画像を確認することができます.
コンポーネントをActivateすると,データの収集が開始されます.
対象物体を把持していなくても,Activateした時点から,動作が開始されてしまうので,
アームが把持を開始したら,対象物体を持たせ,持たせた時点からのデータのみを利用してください.
データ収集を終了する際は,ArmImageGeneratorのコンポーネントをDeactivateまたはExitで終了させてください.
データ収集を終了後に,自動でデータ収集を始めたところまでの画像と“joint.csv”内のデータを削除してください.この時,収集した画像と“joint.csv”のデータの数が一致していることを確認してください.
データ収集の際,カメラ画像には,ピッキングする対象物体以外のものが,できるだけ写り込まないように工夫すると,把持精度が上がります.
5.2学習(Machine Learning,ML)
ダウンロードしたサンプルスクリプトを
$ python sample.py
で実行してください.
学習後に,フォルダ内にできた“ model_log.json”と“param.hdf5”をコピーして,KerasArmImageMotionGeneratorのフォルダ内に配置してください.
5.3タスク遂行実験(Task Execution,TE)
RTM及び4.3で取得したKerasArmImageMotionGenerator,MikataArmRTC,WebCameraRTCの3つのコンポーネントを起動します.
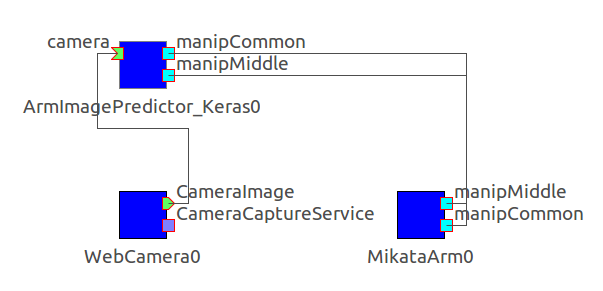
各コンポーネントを上図のように接続します.
正常に作動している場合,KerasArmImageMotionGeneratorを起動しているターミナル上に“Hello?: ”と表示されます.
対象物をセットした後,このターミナル上で“Enter”を押すと,リーチングを開始します.
対象物体が把持できたら,タスク成功です.